
Software application developers and users are now targeting a wide range of diverse computing platforms, such as on-premises supercomputers and clouds with heterogeneous node architectures. Container technology has grown popular as a bridge between these heterogeneous environments due to ease of use, portability, scalability, and the advent of user-friendly runtimes. Containers provide a straightforward way to share scientific applications and reproduce research on either cloud or High-Performance Computing (HPC) systems. Despite this, optimizations within an HPC setting require in-depth knowledge of the system and compatible libraries for any particular system, and applying optimizations specifically targeting the hardware is crucial to performance for compute-intensive applications.
We introduce MODAK (Model Optimised Deployment of Applications in (K)Containers), a software package that aims to manage optimized applications within containers to specifically address the goal of achieving performance on specific target hardware for cloud and HPC systems within the SODALITE project. It works in two phases: an initial phase done by an expert and the user utilization phase. For both phases, the optimization configuration associated with a stored container and the requirement specification by the user is formalized as part of a Domain Specific Language (DSL).
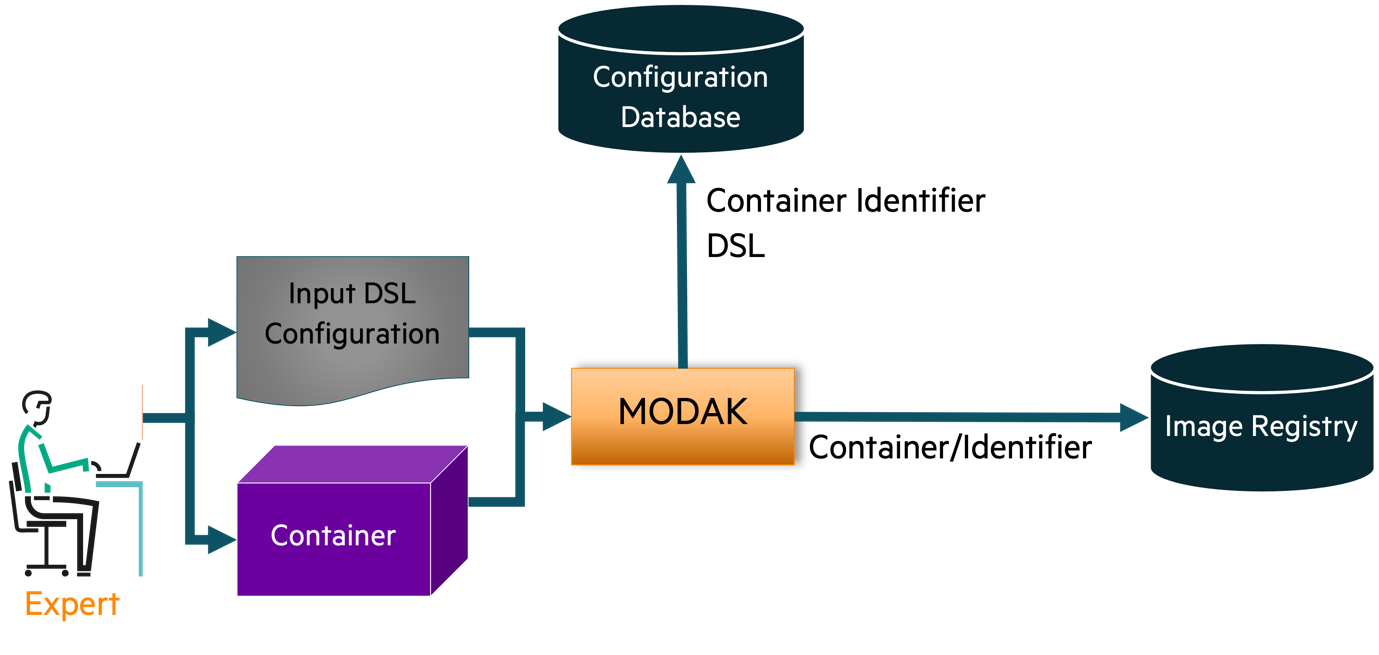
An expert uses MODAK to produce a unique identifier for a new container consisting of a name and tag combination for the container. This identifier, the optimization configuration, and the definition file used to build the container are registered in the MODAK configuration database, while the container is stored independently in a container registry. This phase is shown in Figure 1.
For the user deployment of applications, MODAK is configured via the SODALITE IDE to accept the following inputs (also shown in Figure 2):
- A target definition which can either be: a reference to a specific, pre-registered infrastructure configuration, which allows MODAK to derive most required values to run a workload automatically; or a more complete specification of the target hardware and runtime environment if not providing an infrastructure name.
- Additional queuing system parameters required to run, which are not necessarily part of the infrastructure specification (such as queue and user account names).
- Additional user-data related parameters, such as source or target directory names, data path specification, maximum number of cores or nodes to consider, etc.
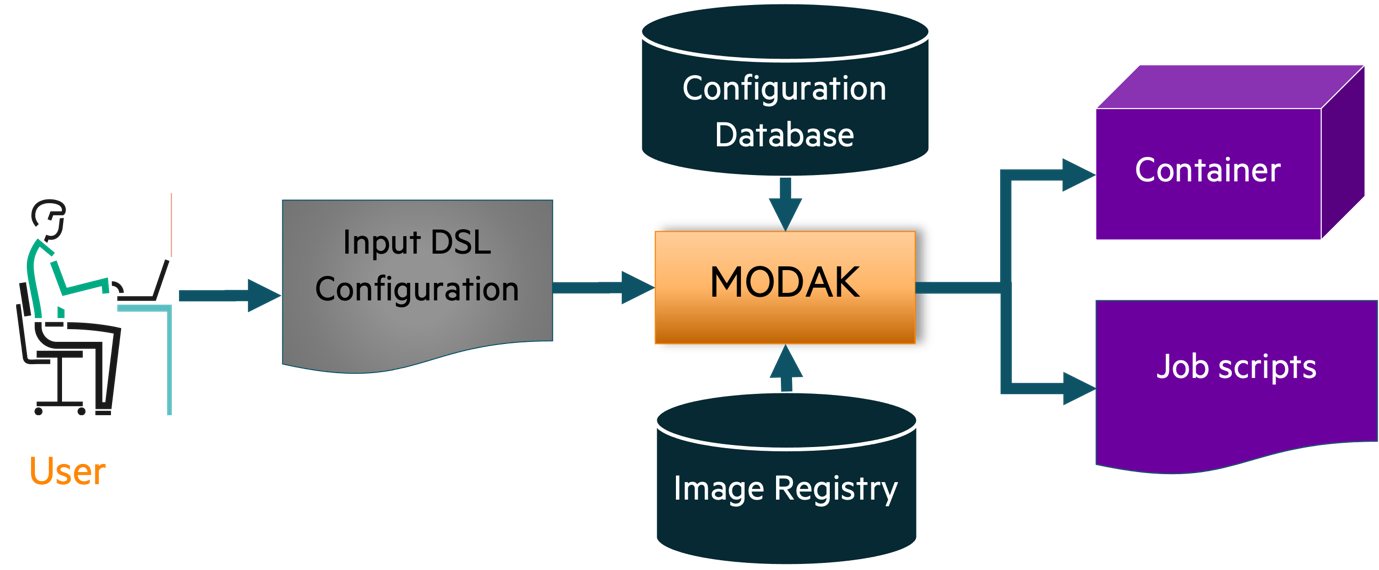
After providing the inputs, MODAK searches the configuration database for an existing container matching the optimization input request. Then, MODAK produces a job script for the execution (e.g. a batch submission script) and returns the link to download the optimized container from the image registry.
Within SODALITE a more concrete example was chosen to proof the efficiency of the container provided by MODAK and to model a real use case. We rebuilt a TensorFlow container from scratch in order to run a Deep Learning classification method which extracts a landscape skyline of a photograph as part of a larger workflow for the Snow detection use case. This container was optimized for the given target architecture, and together with an improved configuration (GPU data prefetching) and early staging data to SSD we achieved a significant speedup compared to the publicly available baseline container. This complete configuration specification was then entered in the MODAK database with the optimized container sent to the image registry.