Links
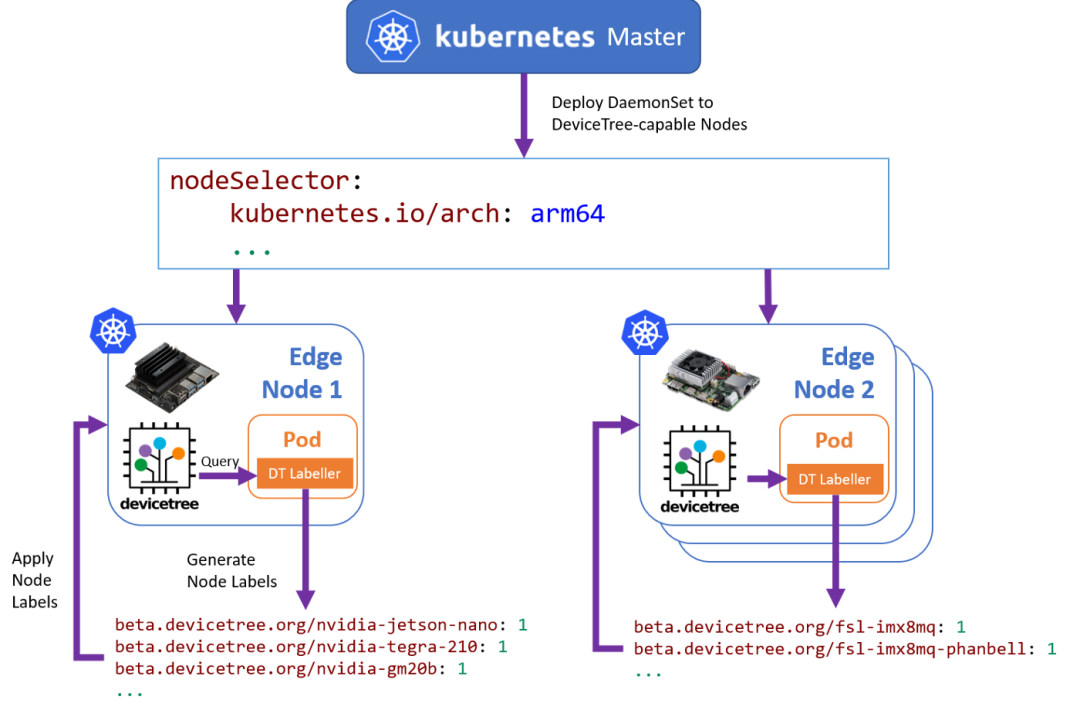
Within the SODALITE H2020 project, one of the areas we are focusing on is the deployment of optimized containers with accelerator-specific ML models for Edge-based inference across heterogeneous Edge Gateways in a Connected Vehicle Fleet. The main motivation for this is three-fold:
- While we can benefit from Cloud and HPC resources for base model training (e.g. TensorFlow), adaptations for specific accelerators are still required (e.g. preparing derivative TFLite models for execution on a GPU or EdgeTPU).
- The lifecycle of a vehicle far exceeds that of a specific Cloud service, meaning that we can not make assumptions about the environment we are deploying into over time.
- Different services may have a stronger need for a specific type of accelerator (e.g. GPU, FPGA), meaning that an existing service may need to be re-scheduled and re-deployed onto an another available resource on a best-fit basis.