
In the last article we introduced the use of devicetree-derived node labels for labelling static features of Edge Gateways but observed that this was not a complete labelling solution given its lack of support for the identification and labelling of devices attached to enumerable busses, such as PCI or USB.
Fortunately, there’s another project that has, at least partially, taken care of this — the Kubernetesnode-feature-discovery (NFD) project. I say partially as it took care of PCI, but we had to write the USB support ourselves. USB support has now been merged for the next release. We take a closer look at NFD below.
In the last article we introduced the use of devicetree-derived node labels for labelling static features of Edge Gateways but observed that this was not a complete labelling solution given its lack of support for the identification and labelling of devic
NFD is, as the name implies, a tool for carrying out node feature discovery across Kubernetes clusters. It accomplishes this by carrying out hardware detection and the extraction of OS configuration information on a per-node basis and communicating these results to the master for labelling.
NFD itself is comprised of two different components:
nfd-masteris the component responsible for carrying out node labellingnfd-workeris the component responsible for carrying out the feature detection and communicating the findings to thenfd-master.
The Git repository for NFD can be found here:

NFD Device Detection
With the USB support integrated, NFD will now, by default, scan for PCI and USB devices that fall under a whitelist of device classes. This is a trade-off between reducing the signal-to-noise ratio and ensuring that devices that are most likely to be used as a basis for informing node selection criteria are exposed.
In the PCI case, the whitelist of classes is:
- Display Controllers
- Processing Accelerators
- Coprocessors
In the USB case, we have generally tried to align with the PCI view, but face a couple of additional challenges:
- The USB base classes give substantially more flexibility to vendors to arbitrarily classify their product.
- Many USB devices do not encode their base class at the device level but instead push this down to the interface level. A USB device may have multiple interfaces, and they do not always implement the same class.
To work around these issues, we have intentionally cast a somewhat wider net on the possible base classes and included interface enumeration that will expose any unique interface that matches the whitelist of class codes. The whitelist of classes is:
- Video
- Miscellaneous
- Application-Specific
- Vendor-Specific
The full list of available codes can be found here. It is further possible to override or extend the list using a custom matching rule, as needed.
NFD Deployment Patterns
NFD can be deployed in a number of different ways:
- As a
Deploymenton the Kubernetes master, in which workers are scheduled as aDaemonSeton each worker node (master labels nodes). - As a self-contained
DaemonSeton each node (nodes label themselves). - As a self-contained
DaemonSetcombined withdt-labellerfor DT-based feature discovery (nodes label themselves with a combined feature set).
These different deployment patterns are further explored in the next section.
NFD as a Master Deployment
The standard deployment pattern is to run NFD as a Deployment on the Kubernetes master that will schedule workers as a DaemonSet on each worker node. In this scenario, nodes discover their features with a node-local instance of the nfd-worker and advertise the detected features to the nfd-master instance running on the Kubernetes master, which in turn is then responsible for applying the labels to the worker nodes. This deployment pattern is exemplified as follows:
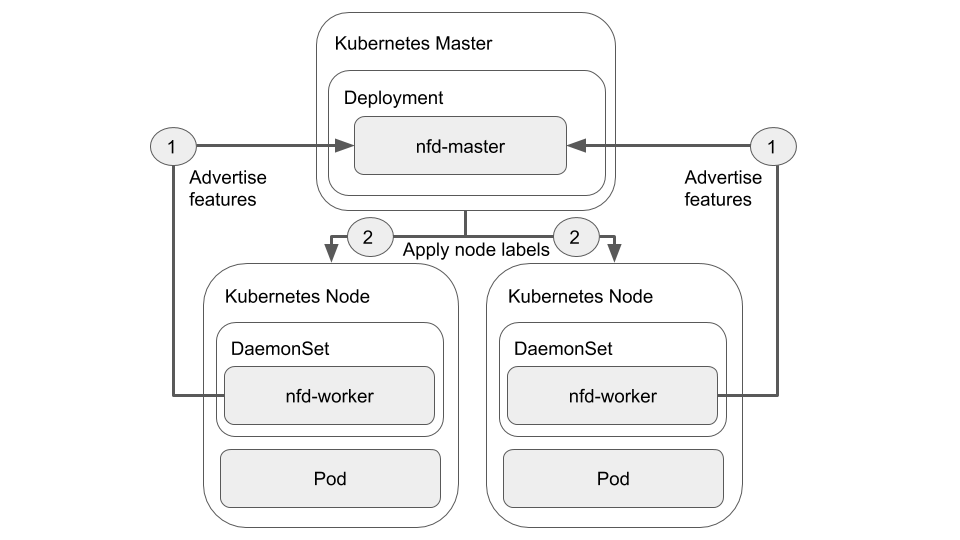
while this model is the standard one, it falls short in a number of areas where Edge deployments are concerned:
- It requires constant connectivity with the Kubernetes master in order to update and maintain the label state, which may be intermittent or periodically interrupted on Edge-based deployments.
- It was largely designed with traditional Cloud-based deployments in mind — principally in-Cloud x86_64-based nodes with PCI, SR-IOV, and other similar features that one would typically expect to find on server-class systems.
- Features more typically encountered on Edge Gateways and SBCs are not well captured or exposed, necessitating tighter coupling with the
dt-labeller.
NFD as a Self-contained Pod
Beyond this, an alternative deployment model aimed at node self-labelling is also provided by NFD. In this case, the nfd-master and nfd-worker are brought together into the same Pod and deployed as a DaemonSet on each node. This pattern is exemplified below:
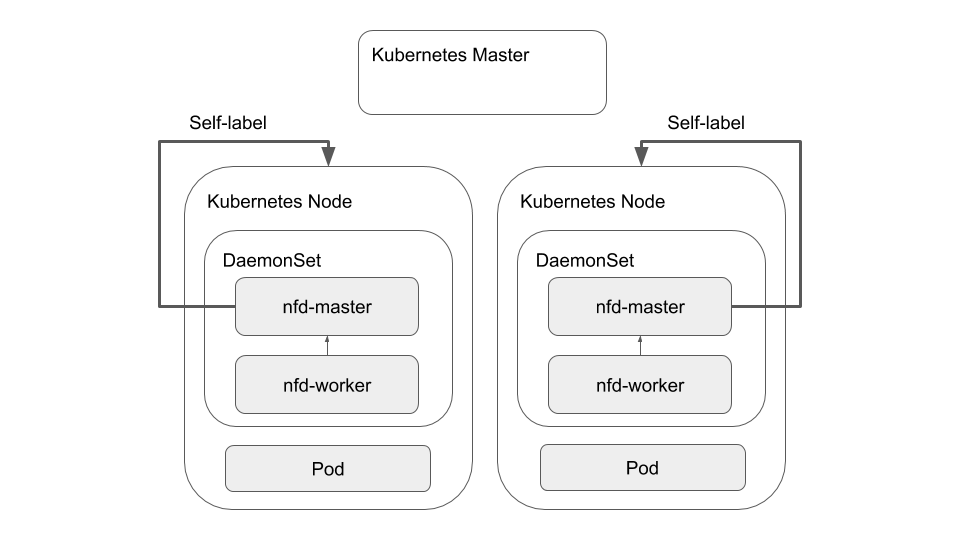
while this deployment model addresses the issue of intermittent connectivity, the remaining limitations mentioned above still apply.
NFD as a Self-contained Pod with DT Feature Discovery
n order to get the best of both worlds, tight coupling between NFD and the dt-labeller is essential. One of the unique features of NFD is the local feature source, which permits for the discovery of custom features either by an executable hook mechanism or via flat files with label/value pairs. As dt-labeller already has a mechanism for doing a dry-run and dumping the discovered label/value pairs for testing purposes, this is trivially extended to write out the features in a way that can be directly parsed by nfd-worker.
Building on the self-contained Pod pattern, we can further insert the dt-labeller into the same Pod to enable feature hand-off. A further benefit is that while the dt-labeller requires privileged access in order to access /sys/firmware, this can be mitigated by running it in one-shot mode from an initContainer, persisting the detected features in a shared volume, and allowing the NFD containers to take over in an unprivileged security context — ultimately allowing us to reduce the security risk of having long-running containers with escalated privileges while retaining full functionality. The combined deployment model is exemplified below:
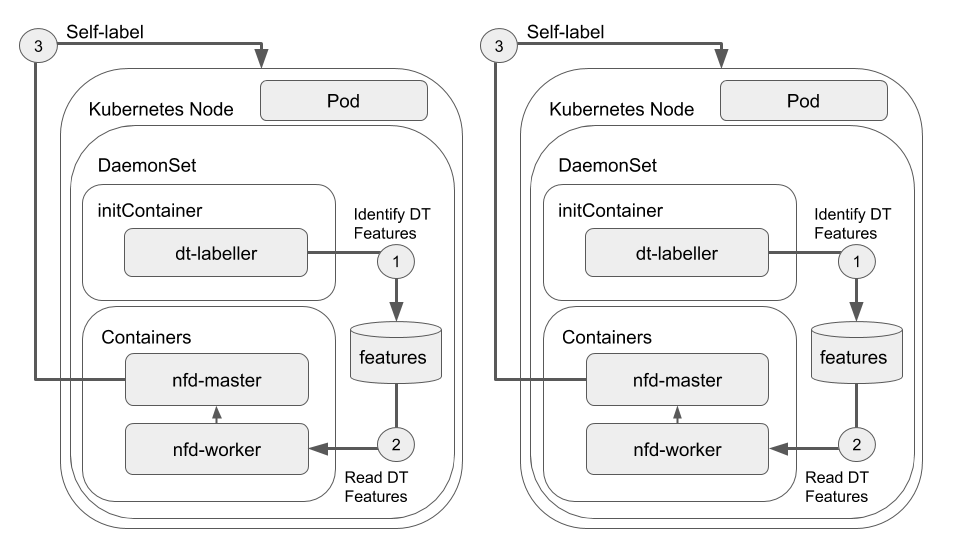
this model can be deployed directly by using the template provided by k8s-dt-node-labeller:
$ kubectl apply -f https://raw.githubusercontent.com/adaptant-labs/k8s-dt-node-labeller/k8s-dt-labeller-nfd.yamlor can be viewed in the git tree:

Putting it all together: Pod Placement targeting Heterogeneous Accelerators in an RPi Cluster
For the following steps, we consider a self-contained Raspberry Pi cluster in which a number of USB-attached AI/ML accelerators are attached. In this particular configuration, we have:
- 4x Raspberry Pi 4 Model B nodes
- 1x Intel NCS2 Accelerator (VPU)
- 1x Coral USB Accelerator (EdgeTPU)
Combining Devicetree and NFD Device Labels
When running on the RPi, we are interested not only on the base model and CPU details but also the type of GPU and the number and type of CPU cores, as these are data points that can be used for identifying specific optimizations that can be applied (our focus within the SODALITE H2020 project). We can test with this configuration to see which labels the dt-labeller discovers:
$ k8s-dt-node-labeller -d -n gpu cpu
Discovered the following devicetree properties:beta.devicetree.org/brcm-bcm2711-vc5: 1
beta.devicetree.org/arm-cortex-a72: 4
beta.devicetree.org/raspberrypi-4-model-b: 1
beta.devicetree.org/brcm-bcm2711: 1
This looks like a reasonable starting point, so we make sure to include these extra DT node specifications as arguments to the labeller in the deployment.
If we look at the logs for dt-labeller we can see that it’s found the features and written them out:
$ kubectl logs nfd-tdzl9 --namespace node-feature-discovery dt-labeller
Writing out discovered features to /etc/kubernetes/node-feature-discovery/features.d/devicetree-features
Doing the same for the nfd-worker we can see that it has successfully picked up the labels and forwarded them to the nfd-masterfor labelling:
2020/05/21 20:54:59 beta.devicetree.org/brcm-bcm2711-vc5 = 1
2020/05/21 20:54:59 beta.devicetree.org/arm-cortex-a72 = 4
2020/05/21 20:54:59 beta.devicetree.org/raspberrypi-4-model-b = 1
2020/05/21 20:54:59 beta.devicetree.org/brcm-bcm2711 = 1
2020/05/21 20:54:59 Sending labeling request to nfd-master
While this process is repeated for every node in the cluster, NFD detects the USB-attached accelerators on two of the nodes:
2020/05/21 20:55:14 usb-fe_1a6e_089a.present = true
2020/05/21 20:55:23 usb-ff_03e7_2485.present = true
and labels the nodes respectively:
$ kubectl describe node rpi-cluster-node2 Name: rpi-cluster-node2 Roles: <none> Labels: beta.devicetree.org/brcm-bcm2711-vc5=1 beta.devicetree.org/arm-cortex-a72=4 beta.devicetree.org/raspberrypi-4-model-b=1 beta.devicetree.org/brcm-bcm2711=1 beta.kubernetes.io/arch=arm64 beta.kubernetes.io/instance-type=k3s beta.kubernetes.io/os=linux k3s.io/hostname=rpi-cluster-node2 k3s.io/internal-ip=192.168.188.100 kubernetes.io/arch=arm64 feature.node.kubernetes.io/usb-fe_1a6e_089a.present=true ...$ kubectl describe node rpi-cluster-node3 Name: rpi-cluster-node3 Roles: <none> Labels: beta.devicetree.org/brcm-bcm2711-vc5=1 beta.devicetree.org/arm-cortex-a72=4 beta.devicetree.org/raspberrypi-4-model-b=1 beta.devicetree.org/brcm-bcm2711=1 beta.kubernetes.io/arch=arm64 beta.kubernetes.io/instance-type=k3s beta.kubernetes.io/os=linux k3s.io/hostname=rpi-cluster-node3 k3s.io/internal-ip=192.168.188.101 kubernetes.io/arch=arm64 feature.node.kubernetes.io/usb-ff_03e7_2485.present=true ...
we can now begin writing node selection criteria that leverage these.
In the last article one of the targets was a Coral AI Dev board, which includes the EdgeTPU as a PCI-attached device, but for which we can also simply use the board model as an additional criterion.
We should always keep in mind the different methods of attachment that an accelerator may have across the cluster when defining the node selection criteria, such that we can define this once and allow Pods to be scheduled regardless of which specific node configuration is ultimately able to satisfy it.
Node Selection vs. Node Affinity
We previously looked at the use of the nodeSelector as the basis for defining increasingly restrictive selection criteria. The benefit of this approach is not only that it’s quite simple, but also that it allows fine-grained placement of containers optimized for very specific configurations. In the case where we would like to constrain a container to a Raspberry Pi 4 Model B with a USB-attached Intel NCS2 Accelerator, this can be expressed as follows:
apiVersion: v1
kind: Pod
metadata:
name: http-echo-rpi4b-ncs2-pod
labels:
app: http-echo
spec:
containers:
- name: http-echo
image: adaptant/http-echo
imagePullPolicy: IfNotPresent
args: [ "-text", "hello from a Raspbery Pi 4B with a USB-attached NCS2 Accelerator" ]
ports:
- containerPort: 5678
nodeSelector:
beta.devicetree.org/raspberrypi-4-model-b: "1"
feature.node.kubernetes.io/usb-ff_03e7_2485.present: "true"This could, however, be made more general — say we want to target an NCS2 on any ARM64-capable node, or we have specific optimizations that only apply to a specific type of ARM core. Each of these aspects can be captured and expressed through the nodeSelector using the DT-provided labels.
While nodeSelector is the most simplistic way to single out specific nodes, it is worth highlighting that it follows a logical AND approach — each of the labels must be satisfied in order for the Pod to be scheduled. In the case where a resource is always attached in the same way, or we have very specific placement requirements, this approach is fine. However, as we see in the case of the EdgeTPU, there are multiple ways in which the EdgeTPU can be attached and discovered.
To address this, we must use the slightly more complex nodeAffinity, which allows node affinity to be determined by a set of labels using a logical OR approach. As long as a node is able to satisfy one of the required labels, the Pod can be scheduled. An example of placing an http-echo Pod on any node with an EdgeTPU can be seen below:
apiVersion: v1
kind: Pod
metadata:
name: http-echo-edgetpu-pod
labels:
app: http-echo
spec:
containers:
- name: http-echo
image: adaptant/http-echo
imagePullPolicy: IfNotPresent
args: [ "-text", "hello from a node with an EdgeTPU" ]
ports:
- containerPort: 5678
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
# USB-attached Coral AI Accelerator
- key: feature.node.kubernetes.io/usb-fe_1a6e_089a.present
operator: In
values: [ "true" ]
- matchExpressions:
# Coral Dev Board
- key: beta.devicetree.org/fsl-imx8mq-phanbell
operator: In
values: [ "1" ]
The specification under requiredDuringSchedulingIgnoredDuringExecution ensures that the selection MUST be met in order for the Pod to be scheduled. In the case where this scheduling is only preferential (perhaps the application has a built-in fallback mechanism in case of resource unavailability), we can instead use preferredDuringSchedulingIgnoredDuringExecution which makes a best effort to schedule onto a matching node, but will still schedule on to any other available node if this fails. We can use this approach when the selection criteria SHOULD be bet, but must not.
More information about node affinity can be found here.
Conclusion
We can see that the combination of NFD and k8s-dt-node-labeller is capable of providing a more comprehensive node labelling solution that can expose not only the underlying platform features of Edge Gateways but also that of connected devices to target during the deployment of optimized containers.
The differences in logical matching approaches between the node selector and node affinity terms provide the flexibility needed to provide everything from fine-grained placement constraints to loosely defined hardware requirements that could be satisfied in a number of different ways during the lifetime of the cluster.
While there remains some work to be done, most of the functionality needed to work with heterogeneous environments at the Edge is already in place and ready to be experimented with.